
STL实现原理及实现
STL提供了六大组件,彼此之间可以组合套用,这六大组件分别是:容器、算法、迭代器、仿函数、适配器(配器)、空间配置器。
STL六大组件的交互关系:
- 容器通过空间配置器取得数据存储空间
- 算法通过迭代器存储容器中的内容
- 仿函数可以协助算法完成不同的策略的变化
- 适配器可以修饰仿函数。
容器
各种数据结构,如vector、Iist、deque、set、map等,用来存放数据,从实现角度来看,STL容器是一种class template。
算法
各种常用的算法,如sort、find、copy、for_each。从实现的角度来看,STL算法是一种function tempalte.
迭代器
扮演了容器与算法之间的胶合剂,共有五种类型,从实现角度来看,迭代器是一种将operator*, operator->, operator++, operator-- 等指针相关操作予以重载的class template。
所有STL容器都附带有自己专属的迭代器,只有容器的设计者才知道如何遍历自己的元素。
原生指针(native pointer)也是一种迭代器。
仿函数
行为类似函数,可作为算法的某种策略。从实现角度来看,仿函数是一种重载了operator()的class或者class template。
适配器
一种用来修饰容器或者仿函数或迭代器接口的东西。
STL提供的queue和stack,虽然看似容器,但其实只能算是一种容器配接器,因为它们的底部完全借助deque, 所有操作都由底层的deque供应。
空间配置器
负责空间的配置与管理。从实现角度看,配置器是一个实现了动态空间配置、空间管理、空间释放的class template。
一般的分配器的std::alloctor都含有两个函数allocate与deallocte,这两个函数分别调用operator new()与delete(),这两个函数的底层又分别是malloc() 和 free(); 但是每次malloc会带来格外开销(因为每次malloc一个元素都要带有附加信息)
空间配置器(allocate())
SGI STL 为了避免小型区块的内存碎片(fragment)问题, SGI设计了两级配置器
当配置区块大于128字节时,调用第一级配置器。小于128字节时调用第二级配置器。
为什么需要二级空间配置器?
我们知道动态开辟内存时,要在堆上申请,但若是我们需要频繁的在堆开辟释放内存,则就会在堆上造成很多外部碎片,浪费了内存空间;
每次都要进行调用malloc、free函数等操作,使空间就会增加一些附加信息,降低了空间利用率;
随着外部碎片增多,内存分配器在找不到合适内存情况下需要合并空闲块,浪费了时间,大大降低了效率。
于是就设置了二级空间配置器,当开辟内存<=128bytes时,即视为开辟小块内存,则调用二级空间配置器。
为什么这样区分成两级?
因为STL容器,一般申请的都会是小块的内存。 二级空间配置器,主要是管理容器申请空间和释放的空间。如果用户申请的空间直接大于的128字节直接找的是一级空间配置器申请空间。
一级空间配置器
第一级配置器(alloc)的allocate()和deallocate()函数只是简单调用malloc()、free()和relloc()函数;
一级空间配置器原理很简单,直接是对malloc和free进行了封装,并且增加了C++中的set_new_handle思想,即申请空间失败抛异常机制。
二级空间配置器
第二级配置器为了降低额外开销(overhead),采用内存池(memory pool)管理内存分配;具体使用的内存块从free-list(自由链表)中提取出。
第二级配置器主动将任何小额区块的内存需求量上调至8的倍数,并维护16个free-list,各自管理大小为8~128bytes的小额区块;
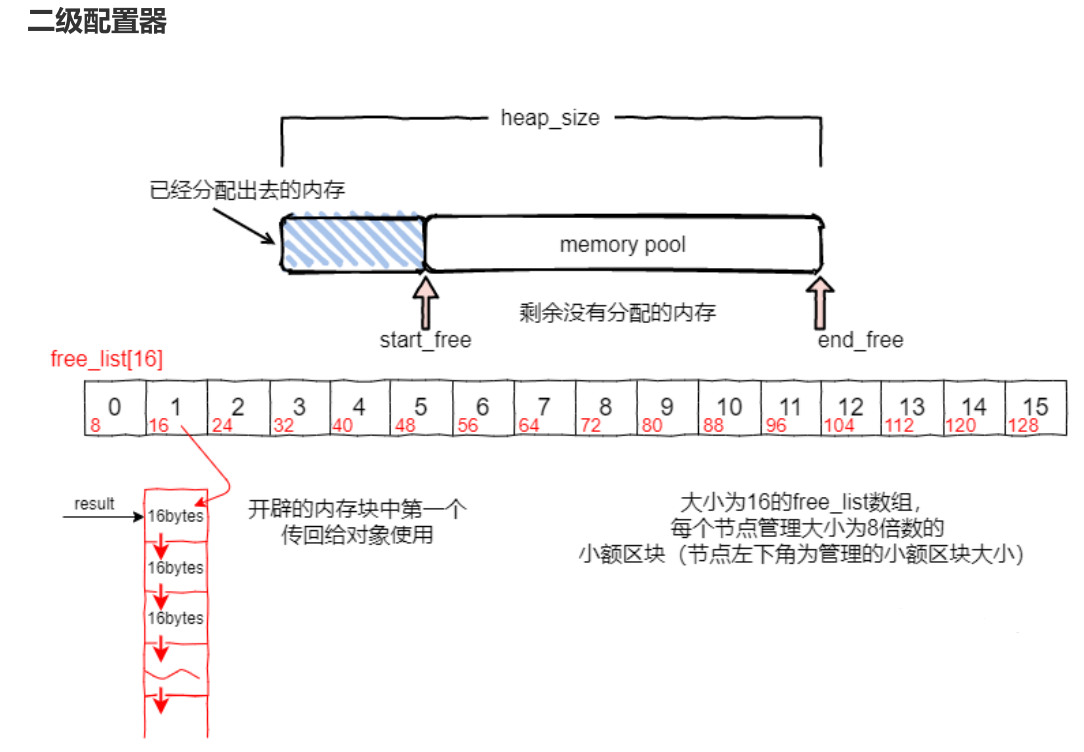
具体流程为:
空间配置函数
allocate(),首先判断区块大小,大于128就直接调用第一级配置器,小于128时就检查对应的free-list。如果free-list之内有可用区块,就直接拿来用,如果没有可用区块,就将区块大小调整至8的倍数,然后调用refill(),为free-list重新分配空间;空间释放函数
deallocate(),该函数首先判断区块大小,大于128bytes时,直接调用一级配置器,小于128bytes就找到对应的free-list然后释放内存。
1.当需要申请的内存大小N 大于128bytes时,直接使用第一级配置器,使用malloc分配
2.小于等于128bytes时,使用内存池管理。内存池管理步骤为:
a. 首先查看是否有可用的free-list,如果有就直接使用。没有的话,将所需区块大小上调至8的倍数,调用 refill()为free list重新分配空间。
b. 新的空间将取自内存池(经由chunk_alloc()完成),如果内存池不够用,从堆空间(malloc配置空间) 拿来补充内存池。如果堆空间也不够了,就调用第一级配置器来补充内存池。因为第一级配置器有out-of- memory处理机制,看看它能不能释放其它内存然后拿来此处使用(如果可以就成功,否则bad_alloc异常)。
这里要注意一点,最初内存池和free list都为空。
迭代器
概念
STL的中心思想:将数据容器(containers)和算法(algorithms)分开,彼此独立设计,最后再以胶着剂将它们撮合在一起。那么之间的胶着剂就是迭代器(iterator)
迭代器 iterator是一种智能指针(smart pointer)
迭代器是一种行为类似指针的对象(智能指针对象),其行为包括内容提领(deference)和成员访问(member access),所以迭代器要对operator&()和operator*()进行重载,同时要兼顾自身的有效性(析构)的问题。
在实际的算法中,在运用迭代器时,会用到迭代器所指对象中的相应类型(associate type)。
那么算法实现中该如何满足 声明一个以“迭代器所指对象(中)的类型”为类型的成员/参数,或返回值是“迭代器所指对象(中)的类型”的类型 的需求呢?
可分为以下三种情况:
① 迭代器所指对象是c++内置类型;
② 迭代器所指对象是自定义类型(class type)情形;
③ 迭代器所指对象是原生指针(naive pointer)情形;
对应的运用以下三种方法解决:
① function template的参数推导(augument deducation)机制 ;
② 声明内嵌类型 ;
③ 利用泛化中偏特化(partial secification)(下面有解释) ;
envolve to :萃取机 iterator_traits 机制
这三种方法是逐步整合为最终的实现的方案就是 *iterator_traits萃取机* 机制,它包含了函数模板的参数推导,声明内嵌类型和偏特化所有内容,也同时解决了以上的三个场景的实现需求。
结合以上三种情况和三种解决方法,最终设计出了迭代器萃取机这一中间层,其作用是萃取出迭代器的相关特性(也即是相应类型的取用),以屏蔽迭代器实现对算法实现的影响
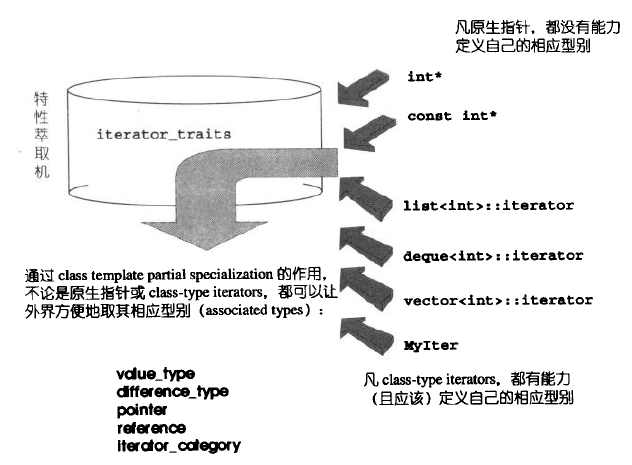
traits技法
traits技法利用“内嵌型别“的编程技巧与编译器的template参数推导功能,增强C++未能提供的关于型别认证方面的能力。常用的有iterator_traits和type_traits。
iterator_traits
被称为特性萃取机,能够方面的让外界获取以下5中型别:
- value_type:迭代器所指对象的型别
- difference_type:两个迭代器之间的距离
- pointer:迭代器所指向的型别
- reference:迭代器所引用的型别
- iterator_category:三两句说不清楚,建议看书
type_traits
关注的是型别的特性,例如这个型别是否具备non-trivial defalt ctor(默认构造函数)、non-trivial copy ctor(拷贝构造函数)、non-trivial assignment operator(赋值运算符) 和non-trivial dtor(析构函数),如果答案是否定的,可以采取直接操作内存的方式提高效率,一般来说,type_traits支持以下5中类型的判断:
1
2
3
4
5__type_traits<T>::has_trivial_default_constructor
__type_traits<T>::has_trivial_copy_constructor
__type_traits<T>::has_trivial_assignment_operator
__type_traits<T>::has_trivial_destructor
__type_traits<T>::is_POD_typ由于编译器只针对class object形式的参数进行参数推到,因此上式的返回结果不应该是个bool值,实际上使用的是一种空的结构体:
1
struct __true_type{};struct __false_type{};
这两个结构体没有任何成员,不会带来其他的负担,又能满足需求,可谓一举两得
当然,如果我们自行定义了一个Shape类型,也可以针对这个Shape设计type_traits的特化版本
1
2
3
4
5
6
7template<> struct __type_traits<Shape>{
typedef __true_type has_trivial_default_constructor;
typedef __false_type has_trivial_copy_constructor;
typedef __false_type has_trivial_assignment_operator;
typedef __false_type has_trivial_destructor;
typedef __false_type is_POD_type;
};
容器
如何选择容器适配器:
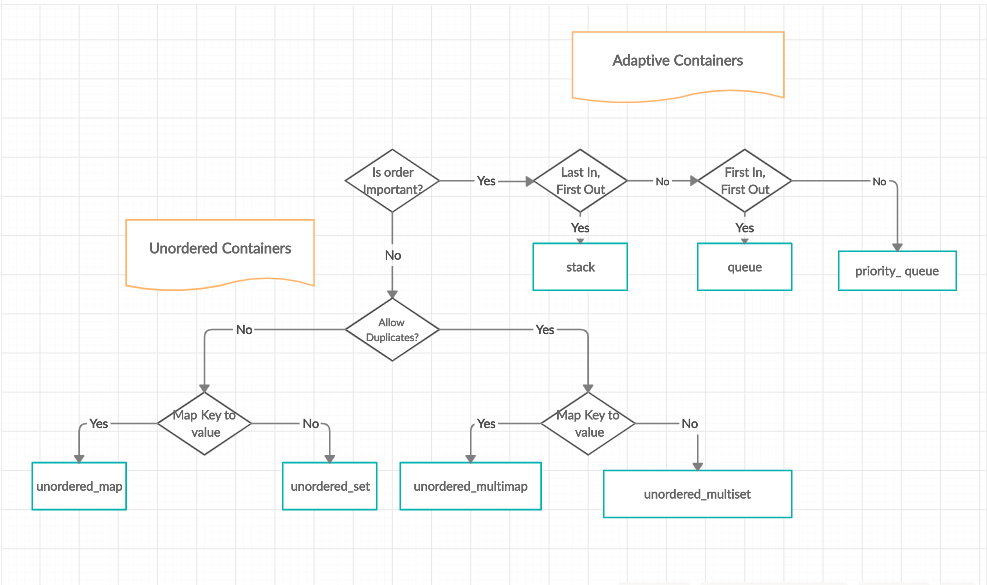
序列式容器
vector - 向量
vector采用的数据结构非常简单,线性连续空间,它以两个迭代器_Myfirst和_Mylast分别指向配置得来的连续空间中已被使用的范围,并以迭代器Myend指向整块连续内存空间的尾端。
为了降低空间配置时的成本,vector实际配置的大小可能比用户端需求大一些,以备将来可能的扩充,这便是容量的概念
所谓动态增加大小,并不是在原空间之后续接新空间(因为无法保证原空间之后尚有可配置的空间),而是一块更大的内存空间,然后将原数据拷贝新空间,并释放原空间。
因此,对vector的任何操作,一旦引起空间的重新配置,指向原vector的所有迭代器就都失效了。
实现细节
vector的底层其实仍然是定长数组,它能够实现动态扩容的原因是增加了避免数量谥出的操作。
首先需要指明的是vector中元素的数量(长度)n与它已分配内存最多能包含元素的数量(容量)N是不一致的,vector会分开存储这两个量。当向vector中添加元素时,如发现n>N,那么容器会分配一个尺寸为2N的数组,然后将旧数据从原本的位置拷贝到新的数组中,再将原来的内存释放。尽管这个操作的渐进复杂度是O(n), 但是可以证明其均摊复杂度为O(1)。而在末尾删除元素和访问元素则都仍然是O(1)的开销。因此,只要对vector的尺寸估
计得当并善用resize()和reserve(),就能使得vector的效率与定长数组不会有太大差距。
长度和容量
vector有两个参数,一个是size,表示当前vector容器内存储的元素个数,一个是capacity,表示当前vector在内存中申请的这片区域所能容纳的元素个数
vector 的reserve增加了vector的capacity,但是它的size没有改变!而resize改变了vector的capacity同时也增加了它的size!
原因如下:
reserve是容器预留空间,但在空间内不真正创建元素对象,所以在没有添加新的对象之前,不能引用容器内的元素。加入新的元素时,要调用 push_back() / insert() 函数。resize是改变容器的大小,且在创建对象,因此,调用这个函数之后,就可以引用容器内的对象了,因此当加入新的元素时,用**operator[]**操作符,或者用迭代器来引用元素对象。此时再调用 push_back() 函数,是加在这个新的空间后面的。
两个函数的参数形式也有区别的,reserve函数之后一个参数,即需要预留的容器的空间;resize函数可以有两个参数,第一个参数是容器新的大小, 第二个参数是要加入容器中的新元素,如果这个参数被省略,那么就调用元素对象的默认构造函数。
1 |
|
reserve()使得vector 预留一定的内存空间,避免不必要的内存拷贝。capacity()返回容器的容量,即不发生拷贝的情况下容器的长度上限。shrink_to_fit()使得vector的容量与长度一致,多退但不会少。
vector的assign()函数用法
函数原型是:
1 | void assign(const_iterator first,const_iterator last); |
第一个相当于个拷贝函数,把first到last的值赋值给调用者;(注意区间的闭合)
第二个把n个x赋值给调用者;
eg:
1 | ls = {0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10} |
排序
- 默认升序排序
1 | sort(nums.begin(), nums.end()); |
- 降序排序
1 | sort(nums.begin(), nums.end(), greater<int>()); |
- 自定义排序规则
1 | //使用lambda函数 |
最大元素(max_element)
1 | //获取最大元素所在迭代器 |
Tips
vector和list由于查找某个元素是O(n)复杂度的,所以不提供
find()。而set和map是由关键字排序,底层是红黑树,进行查找的话时间复杂度是O(logn)所以提供find()vector可以使用泛型find
find(vec.begin(), vec.end(), val) == vec.end();如果vec中存储的是pair 类型,val最好先用
make_pair定义好再去找vector的插入操作可能造成记忆体重新配置,导致原有的迭代器全部失效。
list 的插入操作(insert)和接合操作(splice)都不会造成原有list迭代器失效。甚至list的元素删除操作(erase)也只有“指向被删除元素”的那个迭代器失效,其他迭代器不受任何影响
string - 字符串
头文件<string>
string 和 C风格字符串对比
char*是一个指针,string是一个类string封装了char*,管理这个字符串,是一个char*型的容器。string封装了很多实用的成员方法查找
find,拷贝copy,删除erase,替换replace,插入insert等不用考虑内存释放和越界
string管理char*所分配的内存,每一次string的复制/赋值,取值都由string类负责维护,不用担心复制越界和取值越界等。string本质上是一个动态的char数组。
转char数组
在C语言里,也有很多字符串的函数,但是它们的参数都是char指针类型的,为了方便使用,string有两个成员函数能够将自己转换为char指针– data()/c_str()(它们几乎是一样的,但最好使用c_str(),因为c_str()保证末尾有空字符,而data()则不保证),如:
1 | printf("%s", s); //编译错误 |
获取长度
许多函数可以返回string的长度:s.size() s.length() strlen(s.c_str())
这些函数的复杂度
strlen(s.c_str()) 的复杂度是与字符串长度线性相关的
size() 和 length() 复杂度在C++11中被指定为常数复杂度
寻找某字符(串)第一次出现的位置
1 | s.find('a') //查找字符a第一次出现的位置 |
未找到返回-1
截取子串
substr(pos, len), 这个函数的参数是从pos位置开始截取最多len个字符(如果从pos开始的后缀长度不足len则截取这个后缀)
删除元素
erase(pos)和erase(pos, len)删除字符串中下标为pos开始的指定长度的元素
1 | string s = "123456789" |
1 | string s = "123456789" |
string 和C-style 字符串的转换
- string 转 const char*
1 | string str = "test"; |
- const char* 转 string
1 | const char* cstr = "test"; |
string replace详解
replace算法:
replace函数包含于头文件#include
中。 泛型算法replace把队列中与给定值相等的所有值替换为另一个值,整个队列都被扫描,即此算法的各个版本都在线性时间内执行——其复杂度为O(n)。
即replace的执行要遍历由区间[frist,last)限定的整个队列,以把old_value替换成new_value。
下面说下replace()的九种用法:
用法一:用str替换指定字符串从起始位置pos开始长度为len的字符
1
string& replace (size_t pos, size_t len, const string& str);
用法二: 用str替换 迭代器起始位置 和 结束位置 的字符
1
string& replace (const_iterator i1, const_iterator i2, const string& str);
用法三: 用substr的指定子串(给定起始位置和长度)替换从指定位置上的字符串
1
string& replace (size_t pos, size_t len, const string& str, size_t subpos, size_t sublen);
用法四: 用str替换从指定位置0开始长度为5的字符串 (string转char*时编译器可能会报出警告,不建议这样做)
1
string& replace(size_t pos, size_t len, const char* s);
用法五:用str替换从指定迭代器位置的字符串 (string转char*时编译器可能会报出警告,不建议这样做)
1
string& replace (const_iterator i1, const_iterator i2, const char* s);
用法六:用s的前n个字符替换从开始位置pos长度为len的字符串 (string转char*时编译器可能会报出警告,不建议这样做)
1
string& replace(size_t pos, size_t len, const char* s, size_t n);
用法七:用s的前n个字符替换指定迭代器位置(从i1到i2)的字符串
1
string& replace (const_iterator i1, const_iterator i2, const char* s, size_t n);
用法八:用重复n次的c字符替换从指定位置pos长度为len的内容
1
string& replace (size_t pos, size_t len, size_t n, char c);
用法九: 用重复n次的c字符替换从指定迭代器位置(从i1开始到结束)的内容
1
string& replace (const_iterator i1, const_iterator i2, size_t n, char c);
list - 链表
链表是一种物理存储单元上非连、续非顺序的储存结构,数据元素的逻辑顺序是通过链表中的指针链接次序实现的。
list 容器是一个双向链表,且是循环的双向链表
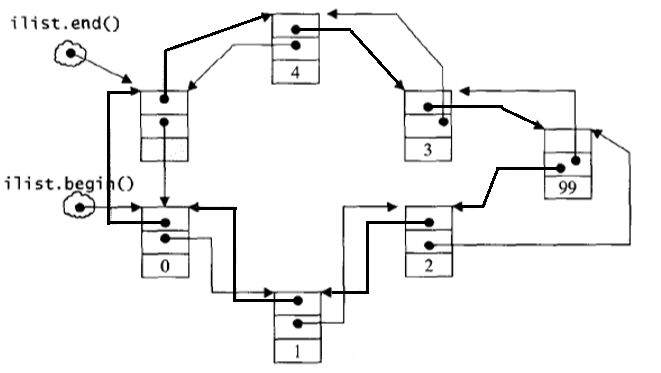
相较于vector的连续线性空间,list就显得复杂许多。
- 它的好处是每次插入或者删除一个元素,就是配置或者释放一个元素的空间
- 因此,list对于空间的运用有绝对的精准,一点也不浪费
- 而且,list对于任何位置插入或删除元素都是常数项时间
list 有一个重要的性质,插入和删除操作都不会造成原有list迭代器的失效
- 这在vector是不成立的,因为vector的插入操作可能会造成内存的重新配置,导致原有的迭代器全部失效
- 而list元素的删除只会使得被删除元素的迭代器失效
遍历
- 顺序遍历
1 | for(list<T>::iterator it = lst.begin(); it != lst.end(); it++) |
- 逆序遍历
1 | for(list<T>::reverse_iterator it = lst.rbegin(); it != lst.rend(); it++) |
构造函数
1 | list<T> lstT; // 默认构造形式,list采用模版类实现 |
元素插入和删除操作
1 | void push_back(T elem); // 在容器尾部加入一个元素 |
赋值操作
1 | assign(beg, end); // 将[beg, end)区间中的数据拷贝赋值给本身 |
反转及排序
1 | void reverse(); // 反转链表 |
1 | // 不能用sort(lst.begin(), lst.end()) |
array - 定长数组
std::array是STL提供的内存连续的、固定长度的数组数据结构,其本质是对原生数组的直接封装。
概念
array实际上是STL对数组的封装。它相比vector牺牲了动态扩容的特性,但是换来了与原生数组几乎一致的性能(在开满优化的前提下)。因此如果能使用C++11特性的情况下,能够使用原生数组的地方几乎都可以直接把定长数组都换成array, 而动态分配的数组可以替换为vector。和其它容器不同,array 容器的大小是固定的,无法动态的扩展或收缩,这也就意味着,在使用该容器的过程无法借由增加或移除元素而改变其大小,它只允许访问或者替换存储的元素。
初始化方式
1 | std::array<double, 10> values; |
成员函数
| 成员函数 | 功能 |
|---|---|
| begin() | 返回指向容器中第一个元素的随机访问迭代器。 |
| end() | 返回指向容器最后一个元素之后一个位置的随机访问迭代器,通常和 begin() 结合使用。 |
| rbegin() | 返回指向最后一个元素的随机访问迭代器。 |
| rend() | 返回指向第一个元素之前一个位置的随机访问迭代器。 |
| cbegin() | 和 begin() 功能相同,只不过在其基础上增加了 const 属性,不能用于修改元素。 |
| cend() | 和 end() 功能相同,只不过在其基础上,增加了 const 属性,不能用于修改元素。 |
| crbegin() | 和 rbegin() 功能相同,只不过在其基础上,增加了 const 属性,不能用于修改元素。 |
| crend() | 和 rend() 功能相同,只不过在其基础上,增加了 const 属性,不能用于修改元素。 |
| size() | 返回容器中当前元素的数量,其值始终等于初始化 array 类的第二个模板参数 N。 |
| max_size() | 返回容器可容纳元素的最大数量,其值始终等于初始化 array 类的第二个模板参数 N。 |
| empty() | 判断容器是否为空,和通过 size()==0 的判断条件功能相同,但其效率可能更快。 |
| at(n) | 返回容器中 n 位置处元素的引用,该函数自动检查 n 是否在有效的范围内,如果不是则抛出 out_of_range 异常。 |
| front() | 返回容器中第一个元素的直接引用,该函数不适用于空的 array 容器。 |
| back() | 返回容器中最后一个元素的直接应用,该函数同样不适用于空的 array 容器。 |
| data() | 返回一个指向容器首个元素的指针。利用该指针,可实现复制容器中所有元素等类似功能。 |
| fill(val) | 将 val 这个值赋值给容器中的每个元素。 |
| array1.swap(array2) | 交换 array1 和 array2 容器中的所有元素,但前提是它们具有相同的长度和类型。 |
deque - 双端队列
概念
- 所谓的双向开口,意思是可以在头尾两端分别做元素的插入和删除操作
- vector 虽然也能在头尾插入元素,但是在头部插入元素的效率很低,需要大量进行移位操作
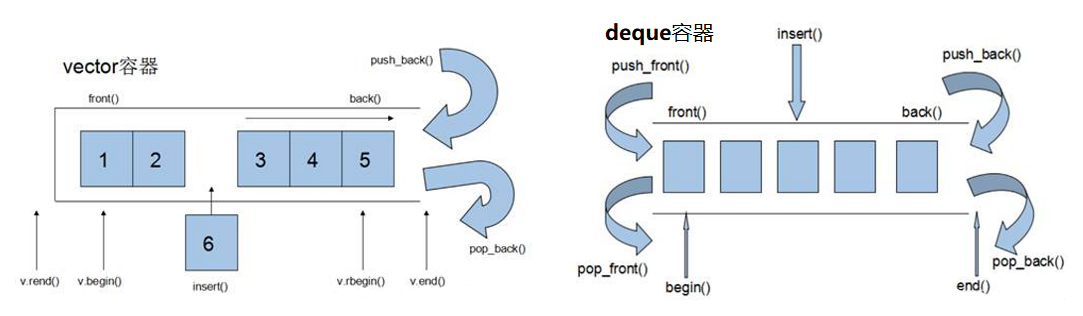
deque 容器和 vector 最大的差异
- deque 允许使用常数项时间在头部插入或删除元素
- deque 没有容量(capacity)的概念,因为它是由动态的分段连续空间组合而成,随时可以增加一块新的空间并链接起来。因此没必要保留(reserve)功能
虽然deque也提供了 Random Access Iterator,但其实现相比于vector要复杂得多,所以需要随机访问的时候最好还是用vector。
对deque进行的排序操作,为了最高效率,可将deque先完整复制到一个vector身上,将vector排序后(利用STL sort算法),再复制回deque
实现原理
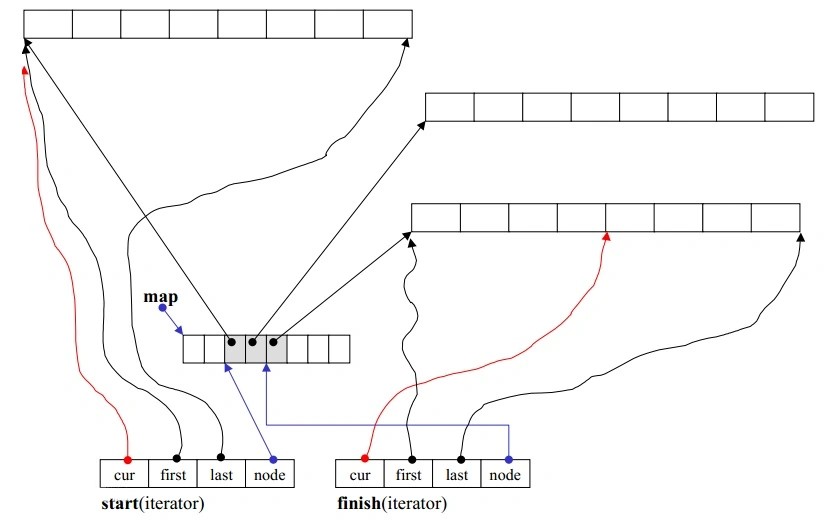
deque 采用一块所谓的map作为主控。deque内部有一个指针指向map,map是一小块连续空间,其中的每个元素称为一个节点node,每个node都是一个指针,指向另一段较大的连续空间,称为缓冲区,这里就是deque中实际存放数据的区域,默认大小512bytes
deque 的数据结构
1 | class deque |
为了实现遍历 deque 容器的功能,deque 迭代器定义了如下的结构:
1 | struct __deque_iterator |
可以看到,迭代器内部包含 4 个指针,它们各自的作用为:
- cur:指向当前正在遍历的元素;
- first:指向当前连续空间的首地址;
- last:指向当前连续空间的末尾地址;
- node:它是一个二级指针,用于指向 map 数组中存储的指向当前连续空间的指针。
迭代器的前进和后退需要注意的是,一旦行进遇到缓冲区边缘,需要特别当心,视前进或后退而定,可能需要调用set_node()跳一个缓冲区
deque 常用API
- 构造函数
1 | deque<T> deqT; // 默认构造函数 |
- 赋值操作
1 | assign(beg, end); // 将[beg, end)区间中的元素拷贝赋值给本身 |
- 大小操作
1 | int size(); // 返回容器中元素的个数 |
- 双端插入和删除操作
1 | push_back(T elem); // 在容器尾部添加一个元素 |
在尾插时只剩一个元素备用空间时,push_back()调用push_back_aux(),先配置一块新的缓冲区,再谈妥新元素内容,然后更迭迭代器finish的状态
在头插时,第一缓冲区若无备用空间,会调用push_front_aux()配置一块新的缓冲区,设定新元素,更改start的状态
注意:头插尾插调用push_front_aux()和push_back_aux()时,再配置缓冲区之前,会先调用reserve_map_at_front()和reserve_map_at_back()来判断检查map是否需要整治(map节点备用空间不足),实际操作由reallocate_map()执行。
- 数据存取
1 | T& at(int idx); // 返回索引idx所指的数据,如果idx越界,抛出out_of_range异常 |
- 插入和删除操作
1 | const_iterator insert(const_iterator pos, T elem); |
insert()函数在某个位置插入一个元素并设定其值,如果插入点是deque前端则交给push_front()去做,如果插入点是deque后端则交给push_back()去做,否则交给insert_aux()去做;
insert_aux()逻辑是比较插入点之前还是插入点之后的元素个数多,选择忘元素个数少的方向移动。
stack - 栈
stack 是一种先进后出(First In Last Out, FILO)的数据结构,它只有一个出口。
stack 容器允许新增元素、移除元素、取得栈顶元素,但是除了最顶端外,没有任何其他方法可以存取stack的其他元素。
stack不允许遍历行为,因此也没有迭代器
SGI STL默认以deque作为stack的底层结构,封闭其开端开口。因此实际上STL stack往往不被归类为container(容器),而被归类为container adapter(配接器)。
除deque外,list也是双向开口的数据结构,以list作为底层结构并封闭其开端开口,一样能够轻易形成stack。
1 | stack<T, list<T> > stk; |
queue - 队列
queue 是一种先进先出(First In First Out, FIFO)的数据结构,它有两个出口,queue容器允许从一端新增元素,从另一端移除元素
只有queue的顶端元素,才有机会被外界去用。queue不提供遍历功能,也不提供迭代器。
SGI STL默认以deque作为queue的底层结构,封闭其底端出口和前端入口。queue同样归类为adapter(配接器)。queue同样可以使用list作为底层结构。
1 | queue<T, list<T> > que; |
heap - 堆
heap并不是STL的容器或者配接器,但却是priority queue的底层实现。并且heap运用的是常用的最大堆以及堆排序的方法
- heap的数据结构是一个最大堆,最大堆就是一个完全二叉树,并且每个父节点都大于它的子节点(左右子节点的大小没有限制,不需要大的子节点一定要放哪边)
- 隐式表示法就是一个二叉树,可以用一个数组来表示
1 | int main() { |
注意:如果heap底层使用array完成,array无法动态改变大小,因此不可以对满载的array进行push_heap()操作。否则会将最后一个元素视为新增元素,并将其余元素视为一个完整的heap结构。
priority_queue - 优先队列
优先队列具有队列的所有特性,包括基本操作,只是在这基础上添加了内部的一个排序,它本质是一个堆实现的,默认情况下利用一个max-heap完成,后者是一个vector表现的完全二叉树。
priority_queue同样是container adapter(配接器),提供的api操作与队列基本相同,也没有迭代器。
定义
1 | priority_queue<Type, Container, Functional> name; |
1 | //升序队列 |
注意:
对于**sort()**函数,传入的第三个参数如果是greater
(),则为降序;对于priority_queue,传入的第三个参数如果是greater ,为小顶堆。 其实在优先队列中,greater是判断父节点是否比子节点值都大,是则swap。
排序
Type为pair
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
using namespace std;
int main()
{
priority_queue<pair<int, int>, vector<pair<int,int> >, greater<pair<int, int> > > a;
pair<int, int> b(1, 2);
pair<int, int> c(1, 3);
pair<int, int> d(2, 5);
a.push(d);
a.push(c);
a.push(b);
while (!a.empty())
{
cout << a.top().first << ' ' << a.top().second << '\n';
a.pop();
}
return 0;
}
/*输出
1 2
1 3
2 5
*/自定义比较顺序
1 |
|
还可以这样写(使用lambda表达式)
1 | auto cmp = [](const pair<int, int>& a, const pair<int, int>& b) { |
也可以这样写
1 | auto cmp = [&nums1, &nums2](const pair<int, int>& a, const pair<int, int>& b) { |
slist - 单向链表
STL中list是双向链表,而slist是单向链表。
区别是slist的迭代器是单向的Forward Iterator,而list的迭代器是双向的Bidirectional Iterator。slist所耗用的空间更小,操作更快。它们共同的特点是,插入、移除、接合等操作并不会造成原有的迭代器失效。
slist插入时,需要从前遍历,找到插入点的位置。为了更快插入,提供了insert_after(),erase_after()。slist提供push_front(),不提供push_back()操作,故其元素次序与元素插入顺序相反。
slisi的迭代器如图所示
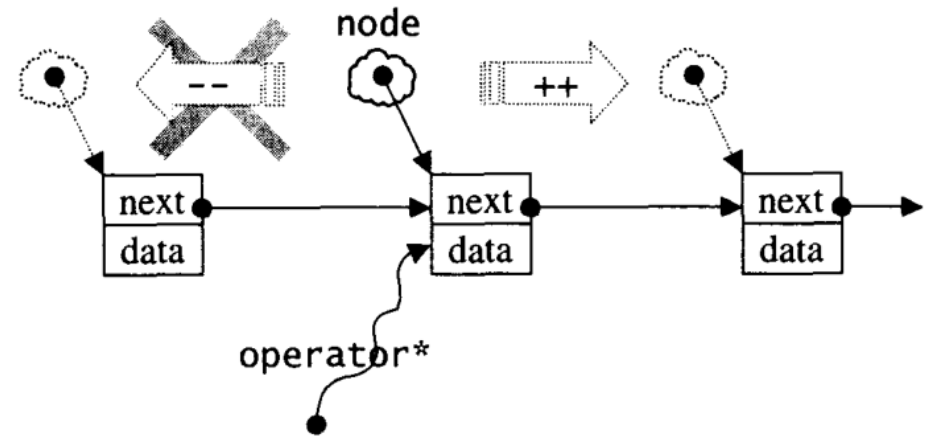
数据结构
slist默认采用alloc空间配置器配置节点的空间,其数据结构主要代码如下:
1 | template <class T, class Allco = alloc> |
需要注意的是C++标准委员会没有采用slist的名称,forward_list在C++ 11中出现,它与slist的区别是没有size()方法。
关联式容器
所谓关联式容器,观念上类似于关联式数据库:每个元素都有一个键值(key)和实值(value)。
pair - 元组
考虑到<key,value>键值对这一特殊形式,STL封装了一个名为pair的模板,其包括first和second两个元素形成一个二元组<first, second>
定义和初始化
1 | 1.定义一个空pair |
成员函数
pair允许对pair对象进行比较操作,包括> < >= <= == !=在比较时,首先比较first元素,然后再比较second元素。注意在比较的时候两个pair的T1与T2类型要严格一致,其不支持自动类型转换。
1 | pair<int, int> p(0, 0); |
set - 集合
红黑树(RB-tree)
红黑树是一颗二叉搜索树,同时满足以下规则:
- 每个节点非红即黑
- 根节点为黑
- 红节点的子节点为黑
- 任何节点到NULL(树尾端)的任何路径,所含黑节点个数相同(黑高度相同)
概念
set的特性是,所有元素都会根据元素的值自动被排序(默认升序),set元素的键值就是实值,实值就是键值,set不允许有两个相同的键值
set不允许迭代器修改元素的值,其迭代器是一种constance iterators
标准的STL set以RB-tree(红黑树)作为底层机制,几乎所有的set操作行为都是转调用RB-tree的操作行为
常用API
- 创建和初始化
1 | *下列初始化都会给出默认排序,实际中可以不写,默认调用std::less<T>,可以根据需要编写自定义的比较 |
- 增删操作
与map不同,set中数据只能通过insert()函数进行插入。
从set中删除元素使用到的函数是erase()函数,主要有以下的几种形式:
1 | • insert(x);//当容器中没有等价元素的时候,将元素 x 插入到 set 中 |
- 查找操作
面对关联式容器,应该使用其所提供的find函数来搜寻元素,会比使用STL算法find()更有效率。因为STL算法find()只是循序搜寻。
1 | • count(x);//返回set内键为x的元素数量。 |
multiset - 多重集合
和 set 容器十分相似,唯一的区别在于,multiset 容器中可以同时存储多(≥2)个键相同的键值对。
需要注意的是,不建议直接修改 multiset 容器的值,因为对于一个 multiset 容器来说,其内部的元素的key与value是相等的,直接修改可能会破坏其排序顺序,因此最好是先删除再添加。
multimap和map的唯一区别就是:multimap调用的是红黑树的insert_equal(),可以重复插入而map调用的则是独一无二的插入insert_unique(),multiset和set也一样,底层实现都是一样的,只是在插入的时候调用的方法不一样。
初始化方式与set并无二致
map - 映射
map的是C++中存储键值对的数据结构。很多情况下,map中存储的键值对通过pair向外暴露。
1 | map<int, double> mp; |
map一般存储的都是pair对象,当存储多个键值对时,该容器会自动根据各键值对的键的大小,按照既定的规则进行排序。默认情况下,map 容器选用std::less<T>排序规则。除此之外,我们可以手动指定 map 容器的排序规则,既可以选用 STL 标准库中提供的其它排序规则(比如std::greater<T>),也可以自定义排序规则。
另外,对于map容器来说,其键(key)是一个被加了const修饰的值,不能被修改,更不能重复,但是value是一个可以被修改的值,并且多个key可以同时对应一个value
常用API
- 构造函数
1 | map<T1, T2> mapTT; // map默认构造函数 |
- 赋值操作
1 | map& operator=(const map& mp); // 重载等号操作符 |
- 大小操作
1 | int size(); // 返回容器中元素的数目 |
- 插入删除操作
1 | pair<iterator, bool> insert(pair<T1, T2> p); // 通过pair的方式插入对象 |
- 查找操作
1 | iterator find(T1 key); |
排序
- 对key值进行特定的排序
map容器里面有两个值一个key一个是value,map<key,value>,其实map里面还有第三个参数,是一个类,用来对map的key进行排序的类
写出一个greater类来让key按照降序排列
1 |
|
- 对value的值进行排序
因为map的模板里面没有对value的值进行排序的参数,所以只能借助sort函数,然而sort函数只能对vector,list,queue等排序,无法对map排序,那么就需要把map的值放入vector中在对vector进行排序,在对vector进行输出,从而间接实现了对map的排序。sort也有第三个参数,跟上面那个map类似,所以可以写一个类或者函数来将其排序。
1 |
|
multimap - 多重映射
和 map 容器十分相似,唯一的区别在于,multimap 容器中可以同时存储多(≥2)个键相同的键值对。
hashtable - 哈希表
概念
基本原理是:使用一个下标范围比较大的数组来存储元素。把关键字Key通过一个固定的算法函数即所谓的哈希函数(散列函数)转换成一个整型数字,然后就将该数字对数组长度进行取余,取余结果就当作数组的下标,将value存储在以该数字为下标的list空间里。也可以简单的理解为,按照关键字key为每一个元素“分类”,然后将这个元素存储在相应“类”所对应的地方,称为桶。
为了避免哈希表太大,需要用到某种映射函数,将大数映射为小数,这种函数称为散列函数hash function。但hash function会带来碰撞问题,即不同的元素被映射到相同位置
为了解决碰撞问题的方法有:线性探测、二次探测、再散列、开链法。
- 线性探测 – 使用hash函数计算出的位置如果已经有元素占用了,则向后依次寻找,找到表尾则回到表头,直到找到一个空位
- 再散列 – 发生冲突时使用另一种hash函数再计算一个地址,直到不冲突
- 开链 – 每个表格维护一个list,如果hash函数计算出的格子相同,则按顺序存在这个list中
- 二次探测 – 使用hash函数计算出的位置如果已经有元素占用了,按照$1^2$、$2^2$、$3^2$…的步长依次寻找,如果步长是随机数序列,则称之为伪随机探测
线性探测法容易产生主集团(primary clustering),二次探测法可能造成次集团(secondary clustering) 问题。
原理
hashtable就是用的开链法,使用开链法,表格的负载系数将大于1。
hashtable中的bucket所维护的list既不是list也不是slist,而是其自己定义的由hashtable_node数据结构组成的linked-list,而bucket聚合体本身使用vector进行存储。hashtable的迭代器只提供前进操作,不提供后退操作。
在hashtable设计bucket的数量上,其内置了28个质数[53, 97, 193,…,429496729],在创建hashtable时,会根据存入的元素个数选择大于等于元素个数的质数作为hashtable的容量(vector的长度),其中每个bucket所维护的linked-list长度也等于hashtable的容量。
如果插入hashtable的元素个数超过了bucket的容量,就要进行重建table操作,即找出下一个质数,创建新的buckets vector,重新计算元素在新hashtable的位置。
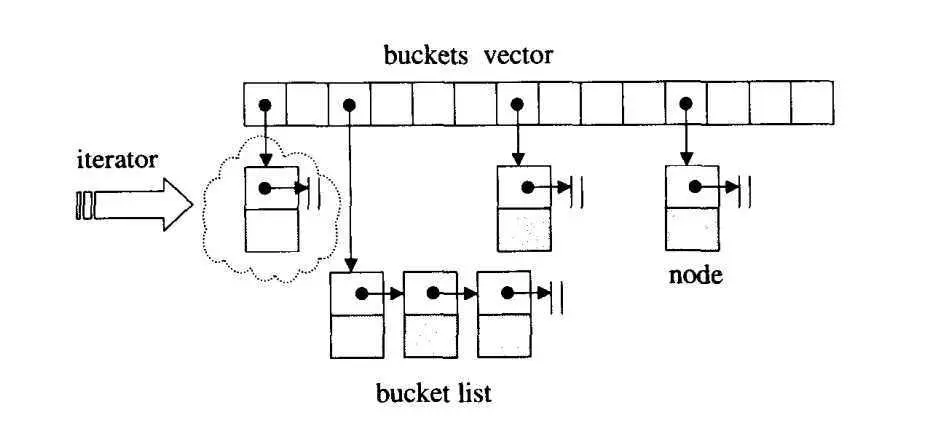
hashtable节点及迭代器的定义
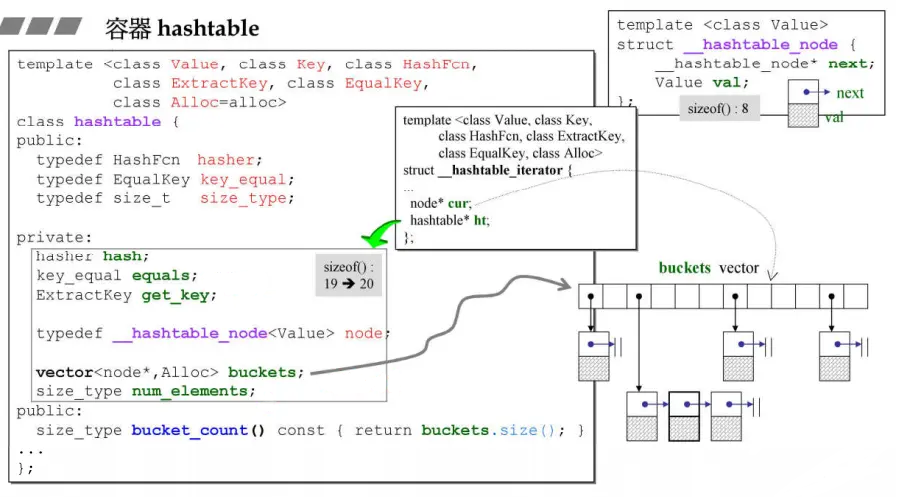
迭代器类型是 **forward_iterator_tag (前向迭代器)**,hashtable的迭代器没有后退操作(operator--()),也没有定义所谓的逆向迭代器(reverse iterator)。
操作
hashtable 的插入 跟 RB-tree 的插入类似,有两种插入方法 insert_unique() 和 insert_equal() ,意思也是一样的,insert_unique() 不允许有重复值,而 insert_equal() 允许有重复值。插入时会判断是否需要重建表格。
判断 “表格重建与否” 是拿元素个数(把新增元素计入后)和 bucket vector 的大小来比,如果前者大于后者,就重建表格 。所以 每个 bucket list 的最大容量和 bucket vector 的大小相同
insert_unique()函数,需要注意的是插入时,新节点直接插入到链表的头节点允许重复插入的
insert_equal(),需要注意的是插入时,重复节点插入到相同节点的后面,新节点还是插入到链表的头节点
注意:hashtable 中,键值相同的元素,一定落在同一个 bucket list 中,但是并不排序
无序关联式容器
自 C++11 标准起,四种基于哈希实现的无序关联式容器正式纳入了 C++ 的标准模板库中,分别是:
unordered_set,unordered_multiset,unordered_map,unordered_multimap
都以hashtable为底层结构
采用哈希存储的特点使得无序关联式容器 在平均情况下 大多数操作(包括查找,插入,删除)都能在常数时间复杂度内完成,相较于关联式容器与容器大小成对数的时间复杂度更加优秀。
在最坏情况下,对无序关联式容器进行插入、删除、查找等操作的时间复杂度会 与容器大小成线性关系!这一情况往往在容器内出现大量哈希冲突时产生。
因此应谨慎使用无序关联式容器,尽量避免滥用(例如懒得离散化,直接将 unordered_map<int, int> 当作空间无限的普通数组使用)
算法
STL算法的一般形式-泛型算法。所有泛型算法的前两个参数都是一对迭代器,通常称为first,last,以标示算法的操作区间,前闭后开。这个[first,last)区间的必要条件是,必须能够经由increment(累加)操作的反复运用,从first到last。编译器本生无法强求这一点,如果这个条件不成立,会导致未可预期的后果
只读算法
- 查找算法
| 算法 | 描述 |
|---|---|
| find(beg, end, v) | 在迭代区间[beg, end)内查找等于v的元素,找到并返回对应的迭代器,否则返回end |
| find_first_of(beg, end, beg2, end2) | 在迭代区间[beg, end)内查找与区间[beg2, end2)内任意元素匹配的元素,然后返回一个迭代器,指向第一个匹配的元素。如果找不到元素,则返回第一个范围的end迭代器 |
| find_end(beg, end, beg2, end2) | 与find_first_of类似,查找最后一个匹配的元素 |
| find_if(beg, end, func) | 函数find的带一个函数参数的_if版本,与find功能相同,条件:使函数func返回true |
- 搜索与统计算法
| 算法 | 描述 |
|---|---|
| search(beg, end, beg2, end2) | 在迭代区间[beg, end)内查找子序列[beg2, end2) |
| search_n(beg, end,n, v) | 在迭代区间[beg, end)内查找连续n个元素v |
| binary_search(beg, end, v) | 试图在已排序的[first, last)中二分查找元素v,找到返回true,否则返回false。 |
| count(beg, end, v) | 统计迭代区间[beg, end)内等于v的元素个数 |
| count_if(beg, end, func) | 函数count的_if版本 |
| lower_bound(beg, end, v) | 进行二分查找非递减序列内第一个大于等于 x 的数的地址/迭代器 |
| upper_bound(beg, end, v) | 进行二分查找非递减序列内第一个大于 x 的数的地址/迭代器 |
| accumulate(beg, end, v) | 累加求和,头两个形参指定要累加的元素范围,第三个形参则是累加的初值,其返回类型就是其第三个实参的类型 |
可变序列算法
| 算法 | 描述 |
|---|---|
| copy(beg, end, beg2) | 将迭代器区间[beg, end)元素复制到以beg2开始的区间 |
| transform(beg, end, beg2, func) | 功能同上,只是每个元素需要经过函数func处理 |
| replace(beg, end, v1, v2) | 将迭代器区间[beg, end)内等于v1的元素替换为v2 |
| fill(beg, end, v) | 区间内元素都写入v |
| fill_n(beg, n, v) | 从位置beg开始的n元素写入v |
| generate(beg, n, rand) | 向从beg开始的n个位置随机填写数据 |
| remove(beg, end) | 移除区间[beg, end)内的元素。注意:并不真正删除 |
| unique(beg, end) | 剔除相邻重复的元素。注意:并不真正删除 |
| iota(beg, end, T) | 用连续的 T 类型值填充序列。前两个参数是定义序列的正向迭代器,第三个参数是初始的 T 值 |
copy,transform,fill_n和generat都需要保证:输出序列有足够的空间。
删除函数并不真正删除元素,只是将要删除的元素移动到容器的末尾,删除元素需要容器擦除函数来操作。同理,独特的函数也不会改变容器的大小,只是这些元素的顺序改变了,是将无重复的元素复制到序列的前端,从而覆盖相邻的重复元素.unique返回的迭代器指向超出无重复的元素范围末端的下一位置
排序算法
STL的sort算法,数据量大时采用快速排序来分段递归排序。一旦分段后的数量小于某个门槛(定义为16),为避免快排的递归调用带来过大的额外负担,就改用插入排序,如果递归层次过深,还会改用堆排序。
| 算法 | 描述 |
|---|---|
| sort(beg, end) | 区间[beg, end)内元素按照字典序排列 |
| stable_sort(beg, end, func) | 同上,不过保存相等元素之间的顺序关系 |
| partial_sort(beg, mid, end) | 将最小的元素顺序放在[beg, mid)内 |
| random_shuffle(beg, end) | 区间内元素随机排序 |
| reverse(beg, end) | 将区间内元素反转 |
| rotate(beg, mid, end) | 将区间[beg, mid)和[mid, end)旋转,使mid作为新的起点 |
| merge(beg, end, beg2, end2, nbeg) | 将有序区间[beg, end)和[beg2, end2)合并到一个新的序列nbeg中,并对其排序 |
关系算法
| 算法 | 描述 |
|---|---|
| equal(beg, end, beg2, end2) | 判断两个区间元素是否相等 |
| includes(beg, end, beg2, end2) | 判断[beg, end)序列是否被第二个序列[beg2, end2)包含 |
| max_element(beg, end) | 返回序列最大元素所在迭代器 |
| min_element(beg, end) | 返回序列最小元素所在迭代器 |
| mismatch(beg, end, beg2, end2) | 查找两个序列中第一个不匹配的元素,返回一对迭代器,标记第一个不匹配元素的位置 |
堆算法
| 算法 | 描述 |
|---|---|
| make_heap(beg, end) | 以区间[beg, end)内元素建立堆 |
| pop_heap(beg, end) | 重新排序堆,使第一个元素与最后一个交换,并不真正弹出最大值 |
| push_heap(beg, end) | 重新排序堆,把新元素放在最后一个位置 |
| sort_heap(beg, end) | 对序列重新排序 |
容器特有算法
- list相关算法
list容器上的迭代器是双向的,而不是随机访问类型。因此,在此容器上不能使用需要随机访问迭代器的算法。这些算法包括sort及其相关的算法。还有一些其他的泛型算法,如合并,删除,反向和唯一,虽然可以用在列上,但却付出了性能上的代价。如果这些算法利用列表容器实现的特点,则可以更高效地执行。
标准库为list容器定义了更精细的操作集合,使它不必只依赖于泛型操作。
| 算法 | 描述 |
|---|---|
| lst.merge(lst2) | 将lst2的元素合并到lst中。这两个容器对象都必须排序。lst2中的元素将被删除。合并后,lst2为空。使用<操作符比较 |
| lst.merge(lst2, cmp) | 同上,使用cmp函数比较排序 |
| lst.remove(val) | 调用lst.erase()删除所有指定值元素 |
| lst.reverse() | 反转lst中的元素 |
| lst.sort() | 对lst中的元素排序 |
| lst.splice(iter, lst2) | 将lst2的元素移到lst的iter所指向元素前面;合并后lst2为空,不能是同一个list |
| lst.splice(iter, lst2, iter2) | 将lst2中iter2所指向的元素移到lst的iter前面;可以是同一个list |
| lst.splice(iter,beg, end) | 将[beg, end)内元素移动到iter前面,如果iter也指向这个区间,则不做任何处理 |
| lst.unique() | 调用erase()删除同一个值的副本。用==操作符比较 |
| lst.unique(func) | 同上,用func函数比较 |
- set相关算法
| 算法 | 描述 |
|---|---|
| set_intersection(beg1, end1, beg2, end2, dest); | 求两个set集合的交集,dest为目标容器开始迭代器,返回目标容器最后一个元素的迭代器地址 |
| set_union(beg1, end1, beg2, end2, dest); | 求两个set集合的并集,dest为目标容器开始迭代器,返回目标容器最后一个元素的迭代器地址 |
| set_difference(beg1, end1, beg2, end2, dest); | 求两个set集合的差集,dest为目标容器开始迭代器,返回目标容器最后一个元素的迭代器地址 |
仿函数
概念
模仿函数的类,使用方式如同函数。本质是类中重载括弧运算符operator()。
- 重载函数调用操作符的类,其对象常称为**函数对象(function object),也叫仿函数(functor)**,使得类对象可以像函数那样调用。
- STL提供的算法往往有两个版本,一种是按照我们常规默认的运算来执行,另一种允许用户自己定义一些运算或操作,通常通过回调函数或模版参数的方式来实现,此时functor便派上了用场,特别是作为模版参数的时候,只能传类型。
- 函数对象超出了普通函数的概念,其内部可以拥有自己的状态(其实也就相当于函数内的static变量),可以通过成员变量的方式被记录下来。
- 函数对象可以作为函数的参数传递。
- 函数对象通常不定义构造和析构函数,所以在构造和析构时不会发生任何问题,避免了函数调用时的运行时问题。
- 模版函数对象使函数对象具有通用性,这也是它的优势之一。
- STL需要我们提供的functor通常只有一元和二元两种。
- lambda 表达式的内部实现其实也是仿函数
内建函数对象
使用时需要包含头文件
<functional>
STL 内建了一些函数对象,分为:
- 算术类函数对象
negate 是一元运算,其他都是二元运算。
1 | template<class T> T plus<T>; // 加法仿函数 |
- 关系运算类函数对象
1 | template<class T> bool equal_to<T>; // 等于 |
- 逻辑运算类函数对象
1 | template<class T> bool logical_and<T>; // 逻辑与 |
案例
仿函数作为set类的比较操作模板
1 |
|
配接器
概念
配接器正如他的名字,在STL中是一个轴承、转换器的角色。Adapter这个概念,实际上是一种设计模式。
在STL中,改变接口,赋予新功能,与其他classes进行兼容。主要包括仿函数配接器(function adapter)、容器配接器(container adapter)、迭代器配接器(iterator adapter)。
- 应用于容器
STL提供的两个容器queue和stack,两者是一种容器配接器,修饰了deque的接口。
class stack封住了所有的deque的对外接口,只开放符合stack原则的几个函数,所以说stack是一个配接器,一个作用于容器之上的配接器。
- 应用于迭代器
insert iterators 可以将一般迭代器的赋值操作转变为插入操作;
reverse iterators 可以将一般迭代器的行进方向逆转,使原本应该前进的operator++变成了后退操作,使原本后退的operator--变成了前进操作;
iostream iterators可以将迭代器绑定到某个iostream对象身上使其拥有输入输出功能。
- 应用于仿函数
functor adapters是所有配接器中数量最庞大的一个,可以不断配接、配接、再配接。这些配接操作包括系结、否定、组合、以及对一般成员函数的修饰(使其成为一个仿函数)。
function adapters的价值在于,通过它们之间的绑定、组合、修饰能力,几乎可以无限制地创造出各种可能的表达式,搭配STL算法一起使用。
可配接的关键
所有期望获得配接能力的组件,本身都必须是可配接的,因此:
- 一元仿函数必须继承自unary_function
- 二元仿函数必须继承自binary_function
- 成员函数必须以mem_fun处理过
- 一般函数必须以ptr_fun处理过。一个未经ptr_fun处理过的一般函数,虽然也可以函数指针的形式传给STL算法使用,但是却没有任何配接能力
案例:
我们希望在每个数据输出的时候加上一个基值,并且该基值由用户输入
1 |
|
仿函数配接器总览

配接器使用解析
