
概念
异常处理就是处理程序中的错误,程序运行时常见异常情况如:
- 做除法的时候除数为 0;
- 用户输入年龄时输入了一个负数;
- 用
new运算符动态分配空间时,空间不够导致无法分配; - 访问数组元素时,下标越界;
- 打开文件读取时,文件不存在。
如果不能发现并加以处理,很可能会导致程序崩溃。
原因
- 当发生异常,程序无法沿着正常的顺序执行下去的时候,立即结束程序可能并不妥当。我们需要给程序提供另外一条可以安全退出的路径,在结束前做一些必要的工作,如将内存中的数据写入文件、关闭打开的文件、释放动态分配的内存空间等。
- 当发生异常的时候,程序马上处理可能并不妥当(一个异常有多种处理方法,或者自己无法处理异常),需要将这个异常抛出给他的上级(直接调用者),由上级决定如何处理。或者是自己不处理再转交给它的上级去处理,一直可以转交到最外层的main()函数
- 另外,异常的分散处理不利于代码的维护,尤其是对于在不同地方发生的同一种异常,都要编写相同的处理代码也是一种不必要的重复和冗余。如果能在发生各种异常时让程序都执行到同一个地方,这个地方能够对异常进行集中处理,则程序就会更容易编写、维护。
在引入异常处理机制之前,异常的处理方式有两种方法
- 使用整型的返回值标识错误;
- 使用
errno宏(可以简单的理解为一个全局整型变量)去记录错误。当然C++中仍然是可以用这两种方法的。
这两种方法最大的缺陷就是会出现不一致问题。例如有些函数返回1表示成功,返回0表示出错;而有些函数返回0表示成功,返回非0表示出错。
还有一个缺点就是函数的返回值只有一个,你通过函数的返回值表示错误代码,那么函数就不能返回其他的值。
鉴于上述原因,C++引入了异常处理机制。
异常处理的基本思想
在遇到异常时,系统不是马上终止运行,而是允许用户排除错误,继续运行程序,至少给出出错的提示信息。
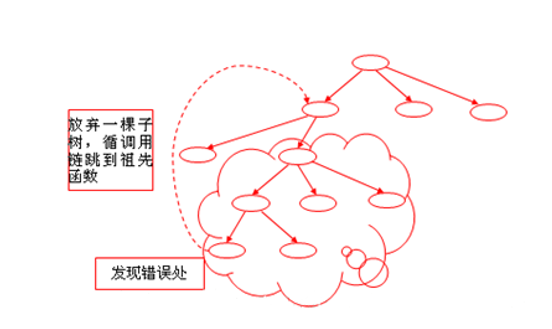
在大型复杂的软件系统中,函数之间有明显的分工和复杂的调用关系,发现错误的函数一般不具备处理错误的能力。
这时只能导致一个异常,并抛出异常,如果调用者也不能处理就传递给它的上级调用者,这样一直上传到能处理为止。
如果始终没有处理就上交到C++运行系统,运行系统调用abort函数强行终止整个程序。
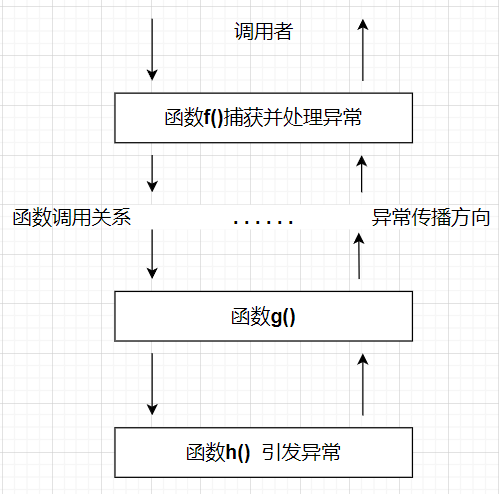
在 h()函数中专注于业务的处理,而不用去处理异常,让 f()函数实现综合的处理.
C++的异常处理机制使得异常的引发和异常的处理不必在同一个函数中,这样底层的函数可以着重解决具体问题,而不必过多的考虑异常的处理。上层调用者可以再适当的位置设计对不同类型异常的处理。
异常是专门针对抽象编程中的一系列错误处理的,C++中不能借助函数机制,因为栈结构的本质是先进后出,依次访问,无法进行跳跃,但错误处理的特征却是遇到错误信息就想要转到若干级之上进行重新尝试。
异常超脱于函数机制,决定了其对函数的跨越式回跳。
错误处理示意
异常处理流程
C++ 异常处理涉及到三个关键字:**try、catch、throw**。
1、throw: 当问题出现时,程序会抛出一个异常。这是通过使用 throw 关键字来完成的。
2、try: try 块中的代码标识将被激活的特定异常。它后面通常跟着一个或多个 catch 块。
3、catch: 在您想要处理问题的地方,通过异常处理程序捕获异常。**catch** 关键字用于捕获异常。
4、finally:关键字finally放在catch之后,如果异常没有被catch捕获,会使用关键字去清理释放资源
如果有一个块抛出一个异常,捕获异常的方法会使用 try 和 catch 关键字。try 块中放置可能抛出异常的代码(判断异常的类型),try 块中的代码被称为保护代码。catch后面对应每个异常的处理方法。
注意:
throw后面可跟任何表达式,除了整数外,指针、字符常量等也可以,如:throw “文档打开失败”。
通过throw操作创建一个异常对象并抛掷
在需要捕捉异常的地方,将可能抛出异常的程序段嵌在try块之中
按正常的程序顺序执行到达try语句,然后执行try块{}内的保护段
如果在保护段执行期间没有引起异常,那么跟在try块后的catch子句就不执行,程序从try块后跟随的最后一个catch子句后面的语句继续执行下去
catch子句按其在try块后出现的顺序被检查,匹配的catch子句将捕获并按catch子句中的代码处理异常(或继续抛掷异常)
如果没有找到匹配,则缺省功能是调用abort终止程序。
异常处理机制语法
1 | 异常发生第一现场,抛出异常 |
案例:
捕获除数为0的异常
1 |
|
Tips:
catch(…)能够捕获多种数据类型的异常对象,所以它提供给程序员一种对异常对象更好的控制手段,使开发的软件系统有很好的可靠性。因此一个比较有经验的程序员通常会这样组织编写它的代码模块,如下:
1 | void Func() |
定义新的异常
exception 是所有C++异常的基类.
1 | class exception { |
您可以通过继承和重载 exception 类来定义新的异常。下面的实例演示了如何使用 std::exception 类来实现自己的异常:
const throw() 不是函数,这个东西叫异常规格说明,表示 what 函数可以抛出异常的类型,类型说明放到 () 里,这里面没有类型,就是声明这个函数不抛出异常,通常函数不写后面的就表示函数可以抛出任何类型的异常。
1 |
|
标准程序库异常的用法
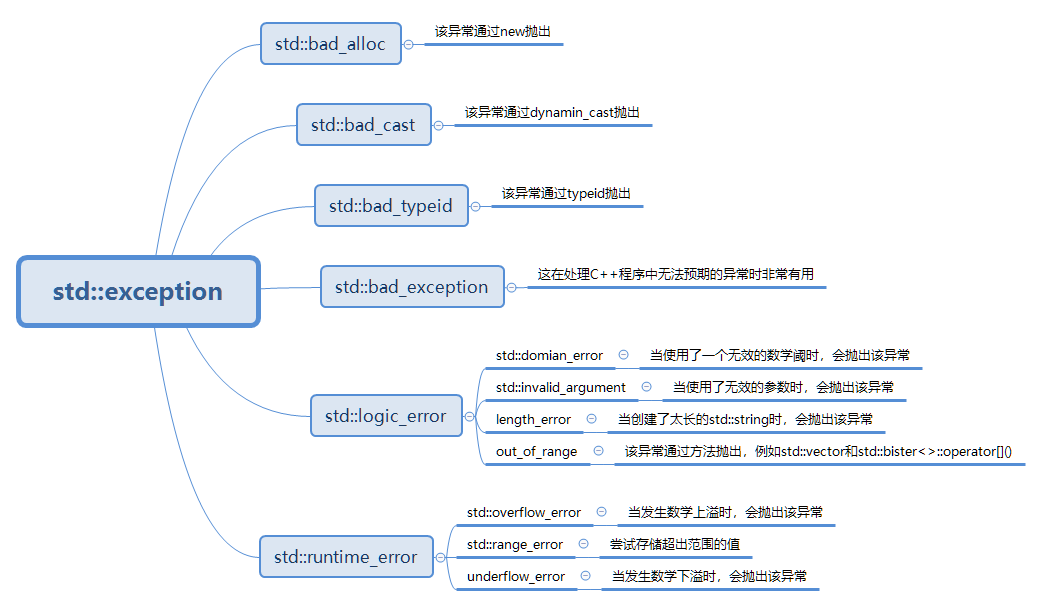
eg:
1 | try{ |
异常处理中的构造与析构
- 异常抛出之前构造异常对象
- catch字句捕获异常时,将异常对象传递给catch形参
- catch字句执行完成,调用异常对象的析构函数,异常对象自动销毁。
几个注意点:
1、栈展开
栈展开指的是:当异常抛出后,匹配catch的过程。
抛出异常时,将暂停当前函数的执行,开始查找匹配的catch子句。沿着函数的嵌套调用链向上查找,直到找到一个匹配的catch子句,或者找不到匹配的catch子句。
栈展开的时候,会通过析构函数或者是delete销毁局部对象(从开始匹配位置到确认匹配这一段中间位置的资源会被释放)
2、析构函数应该从不抛出异常。
如果析构函数中出现异常,那么就应该在析构函数内部将这个异常进行处理,而不是将异常抛出去。
- 如果析构函数抛出异常,则异常点之后的程序不会执行,如果析构函数在异常点之后执行了某些必要的动作比如释放某些资源,则这些动作不会执行,会造成诸如资源泄漏的问题。
- 通常异常发生时,c++的机制会调用已经构造对象的析构函数来释放资源,此时若析构函数本身也抛出异常,则前一个异常尚未处理,又有新的异常,会造成程序崩溃的问题。
3、构造函数可以抛出异常
当构造函数内出现异常,可以选择将异常抛出,在栈展开的过程调用析构函数释放已申请的内存,也可以在内部将异常处理,手动调用delete释放
4、catch捕获所有异常
语法:在catch语句中,使用三个点(…)。即写成:catch (…) 这里三个点是“通配符”,类似 可变长形式参数
5、在 C++11 中,声明一个函数不可以抛出任何异常使用关键字 noexcept
1 | void mightThrow(); // could throw any exceptions. |