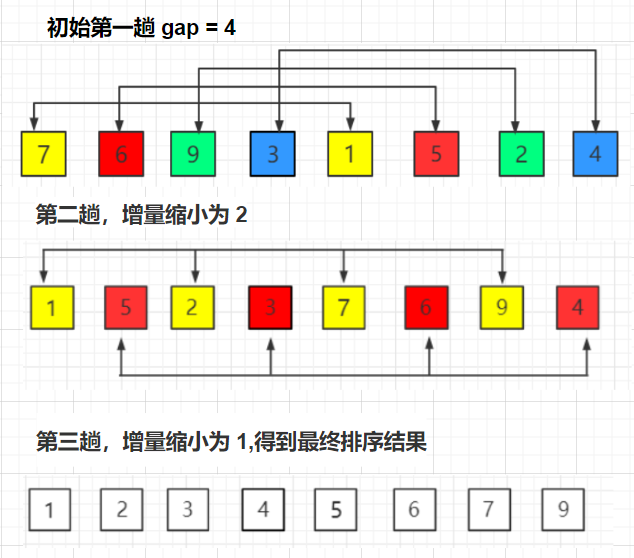
voidshellSort(vector<int> &arr){ int n = arr.size(); int gap = n; while (gap > 1) { // gap > 1 预排序 //最后一次gap = 1 直接插入排序 gap = gap / 2; for (int i = 0; i < n - gap; i++) { int end = i; int tmp = arr[end + gap]; while (end >= 0) { if (arr[end] > tmp) { arr[end + gap] = arr[end]; end -= gap; } elsebreak; } arr[end + gap] = tmp; } } }
voidselectSort(vector<int> &arr){ int n = arr.size(); for (int i = 0; i < n - 1; i++) { int min = i; for (int j = i + 1; j < n; j++) if (arr[j] < arr[min]) min = j; swap(arr[i], arr[min]); } }
voidbubbleSort(vector<int> &arr){ int n = arr.size(); for (int i = 0; i < n; i++) { bool flag = true; //单趟 for (int j = 1; j < n - i; j++) { if (arr[j - 1] > arr[j]) { flag = false; swap(arr[j - 1], arr[j]); } } if (flag) break; //已经有序了 } }
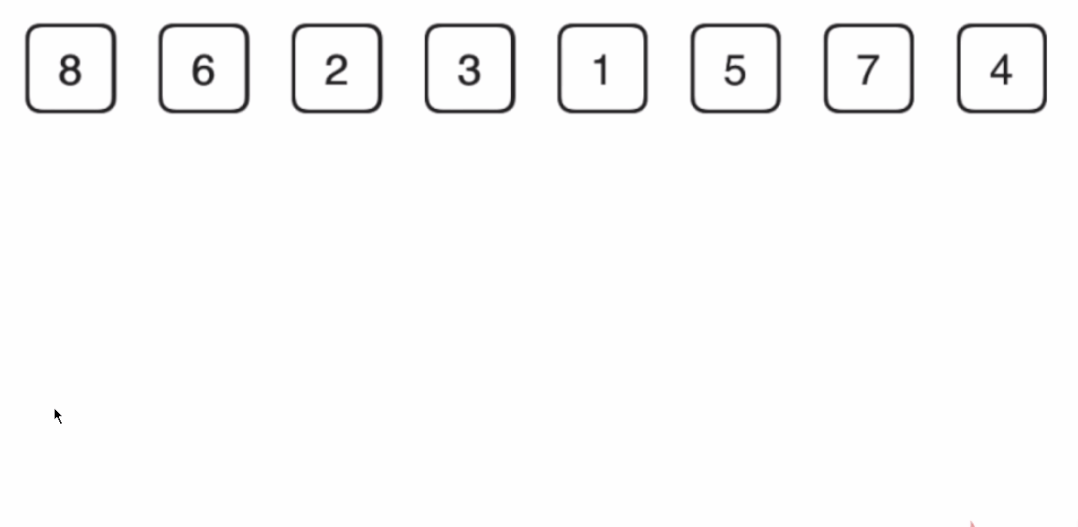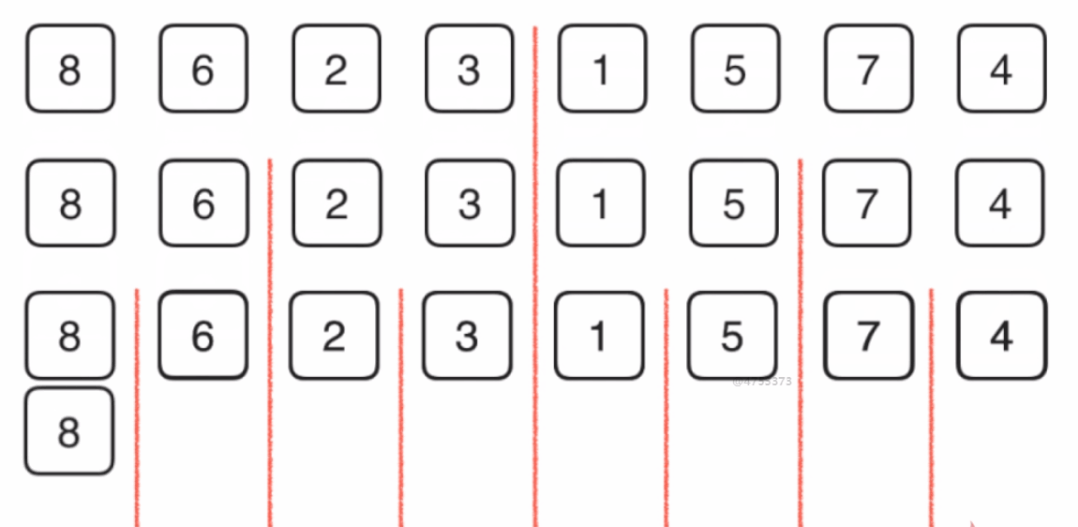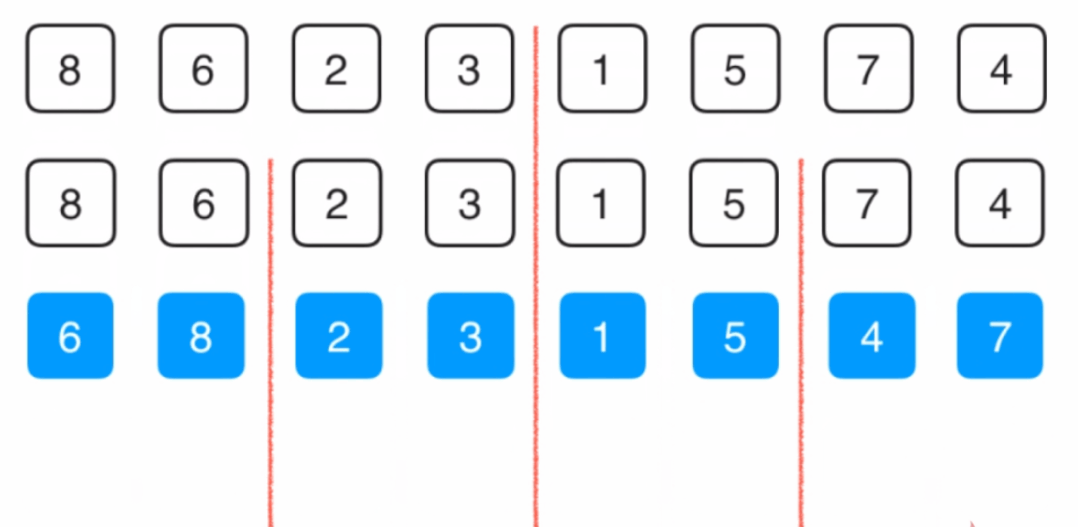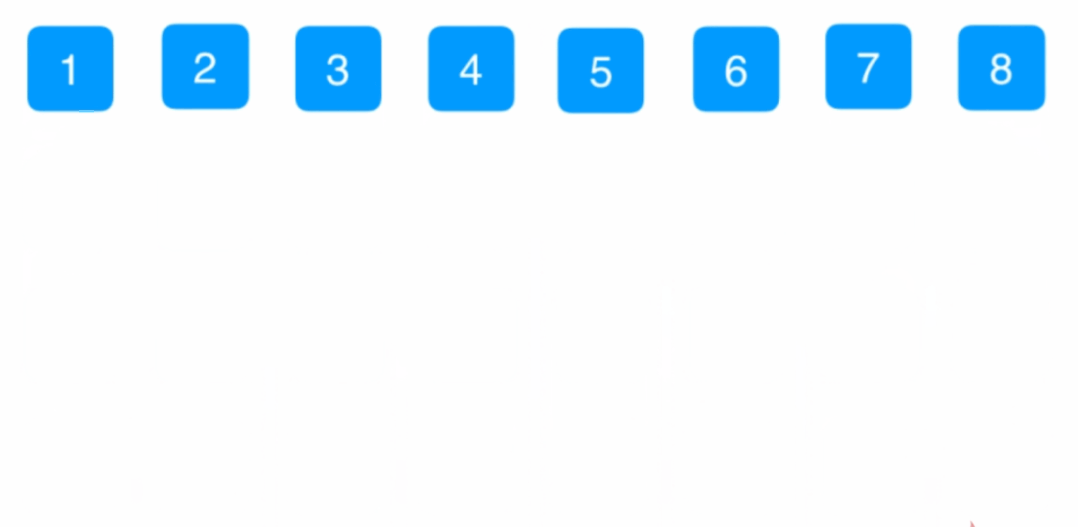
快速排序是由Hoare所发展的一种排序算法。快速排序使用分治法(Divide and conquer)策略。基本思想为:任取待排序元素序列中的某元素作为基准值,按照该排序码将待排序集合分割成两子序列,左子序列中所有元素均小于基准值,右子序列中所有元素均大于基准值,然后最左右子序列重复该过程,直到所有元素都排列在相应位置上为止。
在平均状况下,排序 n 个元素要 Ο(nlogn) 次比较。在最坏状况下则需要 Ο(n^2) 次比较,但这种状况并不常见。事实上,快速排序通常明显比其他 Ο(nlogn) 算法更快,因为它的内部循环(inner loop)可以在大部分的架构上很有效率地被实现出来。
基本实现
采用当前最左侧的元素为划分枢纽,递归法:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
intpartition(vector<int>& arr, int l, int r){ int tmp = arr[l]; //选取最左侧元素为枢纽 while(l < r) { while(l < r && arr[r] >= tmp) r--; arr[l] = arr[r]; while(l < r && arr[l] <= tmp) l++; arr[r] = arr[l]; } arr[l] = tmp; return l; } voidquickSort(vector<int>& arr, int l, int r){ if (l < r) { int mid = partition(arr, l, r); quickSort(arr, l, mid - 1); quickSort(arr, mid + 1, r); } }
单个函数实现快排:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
voidquickSort(vector<int> &arr, int l, int r){ // 子数组长度为 1 时终止递归 if (l >= r) return; // 哨兵划分操作(以 arr[l] 作为基准数) int i = l, j = r; while (i < j) { //顺序不能乱 while (i < j && arr[j] >= arr[l]) j--; while (i < j && arr[i] <= arr[l]) i++; swap(arr[i], arr[j]); } swap(arr[i], arr[l]); // 递归左(右)子数组执行哨兵划分 quickSort(arr, l, i - 1); quickSort(arr, i + 1, r); }
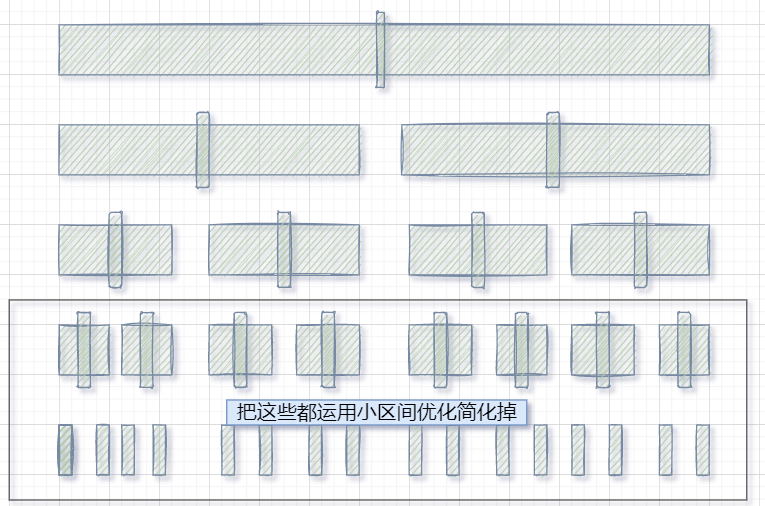
voidmergeSort(vector<int>& arr, int l, int r){ vector<int> tmp(r - l + 1); int gap = 1; int n = r - l + 1; while (gap < n) { //间距为gap为一组,两两归并 for (int i = 0; i < n; i += 2 * gap) { int begin1 = i, end1 = i + gap - 1; int begin2 = i + gap, end2 = i + 2 * gap - 1; //只有end1越界,直接修正 if (end1 >= n) end1 = n - 1; // begin2不存在,第二个区间不存在,修正成一个不存在的区间 if (begin2 >= n) { begin2 = n; end2 = n - 1; } // begin2没事end2越界,修正end2 if (end2 >= n) end2 = n - 1; // 将两段排序合并 int index = i; while (begin1 <= end1 && begin2 <= end2) { tmp[index++] = arr[begin1] <= arr[begin2] ? arr[begin1++] : arr[begin2++]; } while (begin1 <= end1) tmp[index++] = arr[begin1++]; while (begin2 <= end2) tmp[index++] = arr[begin2++]; } // 复制回来原数组 for (int i = 0; i < tmp.size(); ++i) arr[l + i] = tmp[i];
//适用于范围集中的数,排负数也行 voidcountSort(vector<int>& arr){ int n = arr.size(); int minElem = *min_element(arr.begin(), arr.end()); int maxElem = *max_element(arr.begin(), arr.end()); int range = maxElem - minElem + 1; vector<int> cnt(range);
for (int i = 0; i < n; i++) { cnt[arr[i] - minElem]++; }
int index = 0; for (int i = 0; i < range; i++) { while (cnt[i]--) { arr[index++] = i + minElem; } } }
voidinsert(list<int>& bucket, int val){ auto iter = bucket.begin(); while (iter != bucket.end() && val >= *iter) ++iter; // insert会在iter之前插入数据,这样可以稳定排序 bucket.insert(iter, val); }
voidbucketSort(vector<int> &arr){ int len = arr.size(); if (len <= 1) return;
int minElem = *min_element(arr.begin(), arr.end()); int maxElem = *max_element(arr.begin(), arr.end());
int k = 10; // k为数字之间的间隔
//向上取整,例如[0,9]有10个数,(9 - 0)/k + 1 = 1; int bucketsNum = (maxElem - minElem) / k + 1;
vector<list<int>> buckets(bucketsNum); for (int i = 0; i < len; ++i) { int value = arr[i]; //(value-min)/k就是在哪个桶里面 insert(buckets[(value - minElem) / k], value); }
int index = 0; for (int i = 0; i < bucketsNum; ++i) { if (!buckets[i].empty()) { for (auto &value : buckets[i]) arr[index++] = value; } } }
理论上来讲,桶的数量越多,时间复杂度就越低,当然空间复杂度就越高。而且和计数排序很相似,如果桶的数量是 max - min + 1,这个时候,桶排序和计数排序几乎就是一样的。