 前言
前言
背景
很多时候我们需要用python处理二进制数据。例如,存储文件、进行socket操作等。这个时候就需要用到struct模块。
python 中的struct方法主要是用来处理C结构数据的,读入时先转换为Python的 字符串 类型,然后再转换为Python的结构化类型,比如元组(tuple)啥的。一般输入的渠道来源于文件或者网络的二进制流。
struct用途
(1)按照指定格式将Python数据转换为字符串(字节流)。如网络传输时不能直接传输int/long数据,此时要先将int/long转化为字节流,然后再发送;
(2)按照指定格式将字节流转换为Python指定的数据类型;
(3)处理二进制数据,如果用struct来处理文件的话,需要用’wb’,’rb’以二进制(字节流)写,读的方式来处理文件;
(4)处理C或者C++语言中的结构体;
接下来我们介绍struct模块中最重要的pack,unpack两个函数。
方法讲解
在转化过程中,主要用到了一个格式化字符串(format strings),用来规定转化的方法和格式。
struct.pack
1
2
|
struct.pack(fmt, v1, v2, .....)
|
将v1,v2等参数的值进行一层包装,包装的方法由fmt指定。被包装的参数必须严格符合fmt。最后返回一个包装后的字符串。
struct.unpack
1
2
|
struct.unpack(fmt, string)
|
pack打包后,然后就可以用unpack解包了。返回一个由解包数据(string)得到的一个元组(tuple), 即使仅有一个数据也会被解包成元组。其中len(string) 必须等于 calcsize(fmt),这里面涉及到了一个calcsize函数。
struct.calcsize(fmt):这个就是用来计算fmt格式所描述的结构的大小。
如果碰见类似于以下报错:
struct.error: unpack_from requires a buffer of at least 4 bytes
基本就是因为 len(string) 不等于等于 calcsize(fmt) 导致的
fmt说明
格式字符串(format string)由一个或多个格式字符(format characters)组成,对于这些格式字符的描述参照Python manual如下:
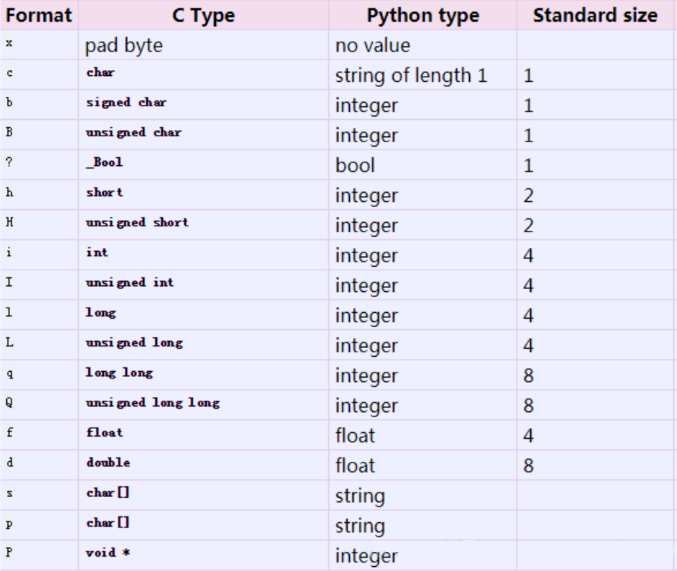
在format string的首位,有一个可选字符来决定大端和小端,列表如下
| @ |
native |
native |
| = |
native |
standard |
| < |
little-endian |
standard |
| > |
big-endian |
standard |
| ! |
network(= big-endian) |
standard |
如果没有附加,默认为@,即使用本机的字符顺序(大端or小端)。
代码示例
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| import struct
buffer = struct.pack( "ihb" , 1 , 2 , 3 )
print repr ( buffer )
print struct.unpack( "ihb" , buffer )
data = [ 1 , 2 , 3 ]
buffer = struct.pack( "!ihb" , * data)
print repr ( buffer )
print struct.unpack( "!ihb" , buffer )
|
首先将参数1,2,3打包,打包前1,2,3明显属于python数据类型中的integer, pack后就变成了C结构的二进制串,转成 python的string类型来显是:‘\x01\x00\x00\x00\x02\x00\x03’。i 代表C struct中的int类型,故而本机占4位,1则表示为01000000; h 代表C struct中的short类型,占2位,故表示为0200; 同理b 代表C struct中的signed char类型,占1位,故而表示为03。
比如程序的后半部分,使用的format string中首位为!,即为大端模式标准对齐方式,故而输出为’\x00\x00\x00\x01\x00\x02\x03’,其中高位自己就被放在内存的高地址位了。
由于本机是小端(‘little- endian’),故数据的高字节保存在内存的高地址中。
大端模式,是指数据的高字节保存在内存的低地址中,而数据的低字节保存在内存的高地址中。
小端模式,是指数据的高字节保存在内存的高地址中,而数据的低字节保存在内存的低地址中。
实际应用
以下为本人实验过程中写的小demo,使用 python实现客户端和服务端的TCP通信,以及发送大包数据。
服务端
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
| import time
import socket
import struct
def get_send_msgflowbytes(length, data):
if length != psize:
print('data lost!')
pass
else:
fmt = "!%dQ" %psize
a = struct.pack(fmt, *data)
return a
def server():
tcp_server_socket = socket.socket(socket.AF_INET,socket.SOCK_STREAM)
tcp_server_socket.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1 )
tcp_server_socket.bind(('server_ip',port))
tcp_server_socket.setsockopt(socket.IPPROTO_TCP,socket.TCP_NODELAY,True)
print('Waiting connecting')
tcp_server_socket.listen(1)
client_socket, client_addr = tcp_server_socket.accept()
print('Someone has connected to this sever')
num = 0
cnt = 0
psize = 1000
while True:
data = list(range(cnt, cnt + psize))
cnt += psize
msg = get_send_msgflowbytes(len(data), data)
print('sending msg:', data[0:1], msg[0:8], len(data))
client_socket.send(msg)
time.sleep(1)
client_socket.close()
if __name__=='__main__':
server()
|
客户端
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
| import socket
import struct
def client():
tcp_socket = socket.socket(socket.AF_INET,socket.SOCK_STREAM)
server_addr = ('server_ip',port)
print('Connecting server')
tcp_socket.connect(server_addr)
print('Connected sonmeone!')
while True:
recv_data = tcp_socket.recv(1000, socket.MSG_WAITALL)
psize = int(len(recv_data) / 8)
fmt = "!%dQ" %psize
msg = struct.unpack(fmt, recv_data)
print('package length:', psize, 'First bunchid:', msg[0:1], 'First raw data:', recv_data[0:8] )
tcp_socket.close()
if __name__=='__main__':
client()
|
发送和接收缓冲区
例如:
1
2
3
4
5
6
7
8
9
10
|
tcp_socket.setsockopt(socket.SOL_SOCKET, socket.SO_RCVBUF,8388608)
tcp_socket.setsockopt(socket.SOL_SOCKET, socket.SO_SNDBUF,8388608)
recv_buff = tcp_socket.getsockopt(socket.SOL_SOCKET, socket.SO_RCVBUF)
send_buff = tcp_socket.getsockopt(socket.SOL_SOCKET, socket.SO_SNDBUF)
print(recv_buff, send_buff)
|
注意,实际上系统默认会设置buffer大小是你设置的两倍。